
Collective Communication with Ignite
In this tutorial, we will see how to use advanced distributed functions like all_reduce(), all_gather(), broadcast() and barrier(). We will discuss unique use cases for all of them and represent them visually.
Required Dependencies
!pip install pytorch-ignite
Imports
import torch
import ignite.distributed as idist
All Reduce
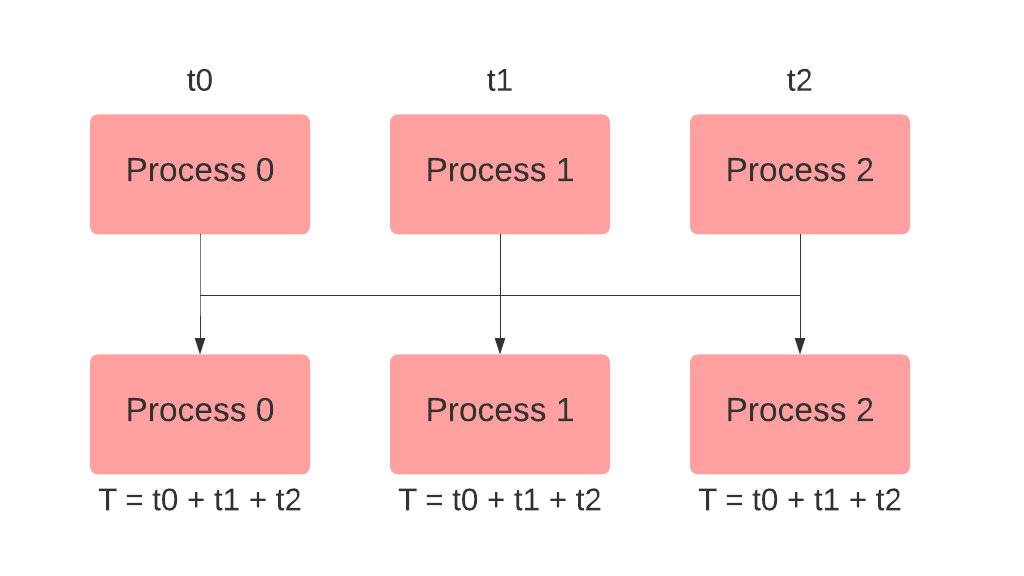
The
all_reduce() method is used to collect specified tensors from each process and make them available on every node then perform a specified operation (sum, product, min, max, etc) on them. Let’s spawn 3 processes with ranks 0, 1 and 2 and define a tensor on all of them. If we performed all_reduce with the operation SUM on tensor then tensor on all ranks will be gathered, added and stored in tensor as shown below:
def all_reduce_example(local_rank):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * local_rank
print(f"Rank {local_rank}, Initial value: {tensor}")
idist.all_reduce(tensor, op="SUM")
print(f"Rank {local_rank}, After performing all_reduce: {tensor}")
We can use
idist.spawn to spawn 3 processes (nproc_per_node) and execute the above function.
idist.spawn(backend="gloo", fn=all_reduce_example, args=(), nproc_per_node=3)
Rank 0, Initial value: tensor([1, 2])
Rank 2, Initial value: tensor([5, 6])
Rank 1, Initial value: tensor([3, 4])
Rank 0, After performing all_reduce: tensor([ 9, 12])
Rank 1, After performing all_reduce: tensor([ 9, 12])
Rank 2, After performing all_reduce: tensor([ 9, 12])
Now let’s assume a more real world scenario - You need to find the average of all the gradients available on different processes.
First, we get the number of GPUs available, with the get_world_size method. Then, for every model parameter, we do the following:
- Gather the gradients on each process
- Apply the sum operation on the gradients
- Divide by the world size to average them
Finally, we can go on to update the model parameters using the averaged gradients!
You can get the number of GPUs (processes) available using another helper method
idist.get_world_size() and then use all_reduce() to collect the gradients and apply the SUM operation.
def average_gradients(model):
num_processes = idist.get_world_size()
for param in model.parameters():
idist.all_reduce(param.grad.data, op="SUM")
param.grad.data = param.grad.data / num_processes
All Gather
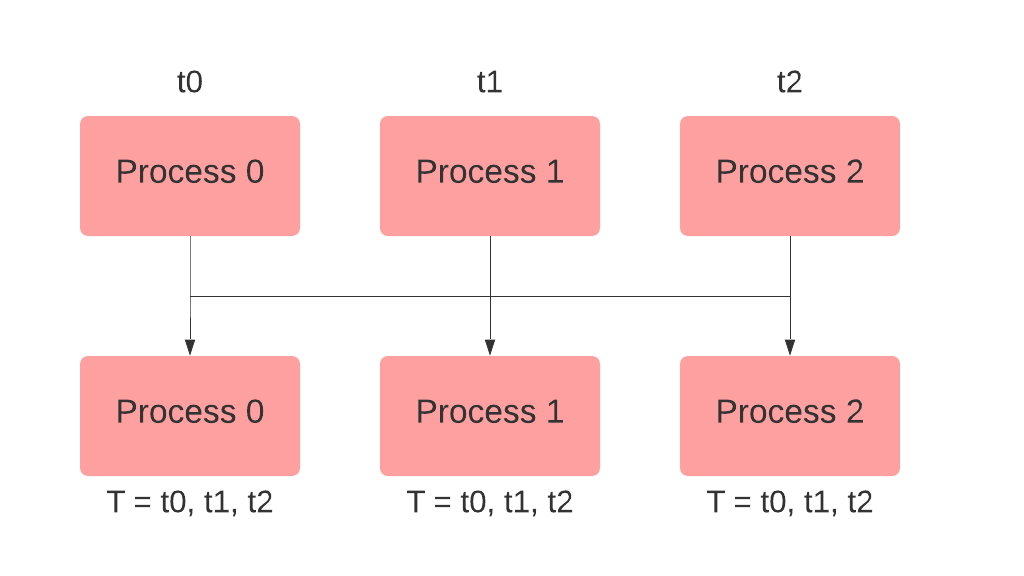
The
all_gather() method is used when you just want to collect a tensor, number or string across all participating processes. As a basic example, suppose you have to collect all the different values stored in num on all ranks. You can achieve this by using all_gather as below:
def all_gather_example(local_rank):
num = 2.0 * idist.get_rank()
print(f"Rank {local_rank}, Initial value: {num}")
all_nums = idist.all_gather(num)
print(f"Rank {local_rank}, After performing all_gather: {all_nums}")
idist.spawn(backend="gloo", fn=all_gather_example, args=(), nproc_per_node=3)
Rank 0, Initial value: 0.0
Rank 2, Initial value: 4.0
Rank 1, Initial value: 2.0
Rank 2, After performing all_gather: [0.0, 2.0, 4.0]
Rank 0, After performing all_gather: [0.0, 2.0, 4.0]
Rank 1, After performing all_gather: [0.0, 2.0, 4.0]
Now let’s assume you need to gather the predicted values which are distributed across all the processes on the main process so you could store them to a file. Here is how you can do it:
def write_preds_to_file(predictions, filename):
prediction_tensor = torch.tensor(predictions)
prediction_tensor = idist.all_gather(prediction_tensor)
if idist.get_rank() == 0:
torch.save(prediction_tensor, filename)
Note: In the above example, only the main process required the gathered values and not all the processes. This can also be done via the gather() method.
Broadcast
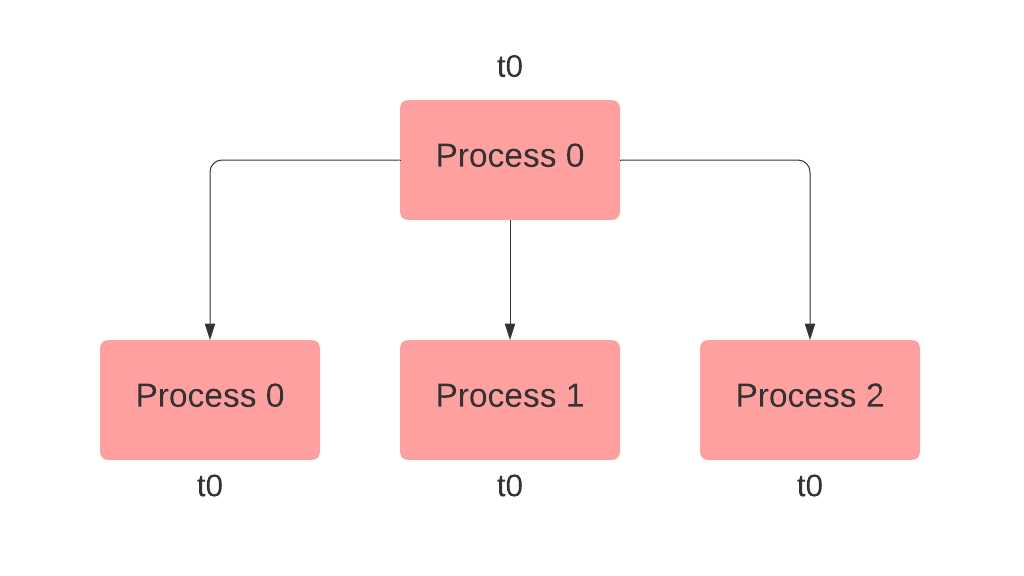
The
broadcast() method copies a tensor, float or string from a source process to all the other processes. For example, you need to send a message from rank 0 to all other ranks. You can do this by creating the actual message on rank 0 and a placeholder on all other ranks, then broadcast the message mentioning a source rank. You can also use safe_mode=True in case the placeholder is not defined on all ranks.
def broadcast_example(local_rank):
message = f"hello from rank {idist.get_rank()}"
print(f"Rank {local_rank}, Initial value: {message}")
message = idist.broadcast(message, src=0)
print(f"Rank {local_rank}, After performing broadcast: {message}")
idist.spawn(backend="gloo", fn=broadcast_example, args=(), nproc_per_node=3)
Rank 1, Initial value: hello from rank 1
Rank 2, Initial value: hello from rank 2
Rank 0, Initial value: hello from rank 0
Rank 2, After performing broadcast: hello from rank 0
Rank 0, After performing broadcast: hello from rank 0
Rank 1, After performing broadcast: hello from rank 0
For a real world use case, let’s assume you need to gather the predicted and actual values from all the processes on rank 0 for computing a metric and avoiding a memory error. You can do this by first using all_gather(), then computing the metric and finally using broadcast() to share the result with all processes. src below refers to the rank of the source process.
def compute_metric(prediction_tensor, target_tensor):
prediction_tensor = idist.all_gather(prediction_tensor)
target_tensor = idist.all_gather(target_tensor)
result = 0.0
if idist.get_rank() == 0:
result = compute_fn(prediction_tensor, target_tensor)
result = idist.broadcast(result, src=0)
return result
Barrier
The
barrier() method helps synchronize all processes. For example - while downloading data during training, we have to make sure only the main process (rank = 0) downloads the datasets to prevent the sub processes (rank > 0) from downloading the same file to the same path at the same time. This way all sub processes get a copy of this already downloaded dataset. This is where we can utilize barrier() to make the sub processes wait until the main process downloads the datasets. Once that is done, all the subprocesses instantiate the datasets, while the main process waits. Finally, all the processes are synced up.
def get_datasets(config):
if idist.get_local_rank() > 0:
idist.barrier()
train_dataset, test_dataset = get_train_test_datasets(config["data_path"])
if idist.get_local_rank() == 0:
idist.barrier()
return train_dataset, test_dataset