How to use Loggers
This how-to guide demonstrates the usage of loggers with Ignite. As part of this guide, we will be using the ClearML logger and also highlight how this code can be easily modified to make use of other loggers. You can see all the other loggers supported here.
In this example, we will be using a simple convolutional network on the MNIST dataset to show how logging works in Ignite.
Prerequisities
- Refer to the installation-guide to install Ignite (and Pytorch).
- To get started with ClearML create your account here. Then create a credential: Profile > Create new credentials > Copy to clipboard.
Install dependencies
%%capture
! pip install torchvision
%%capture
! pip install clearml
%%capture
! clearml-init # You may want to run this command on your terminal separately and paste what you copied in the step above.
Imports
import torch
import torch.nn.functional as F
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import Compose, Normalize, ToTensor
from ignite.contrib.handlers.clearml_logger import (
ClearMLLogger,
ClearMLSaver,
GradsHistHandler,
GradsScalarHandler,
WeightsHistHandler,
WeightsScalarHandler,
global_step_from_engine,
)
from ignite.engine import Events, create_supervised_evaluator, create_supervised_trainer
from ignite.handlers import Checkpoint
from ignite.metrics import Accuracy, Loss
from ignite.utils import setup_logger
Model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
Dataloader
def get_data_loaders(train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
train_loader = DataLoader(
MNIST(download=True, root=".", transform=data_transform, train=True), batch_size=train_batch_size, shuffle=True
)
val_loader = DataLoader(
MNIST(download=False, root=".", transform=data_transform, train=False), batch_size=val_batch_size, shuffle=False
)
return train_loader, val_loader
Training
Ignite makes use of handlers to configure what we want to log. Each handler takes takes in some common attributes like:
- Engine Object, which could for example be the trainer if we are interested in training logs
- Event Name, through which we tell when do we want the information to be logged, for example
event_name=Event.ITERATION_COMPLETED(every=100)would mean that we want the information to be logged every 100 iterations. - args (or kwargs), using which you pass some metadata and provide information of what is to be logged, for example to log the ‘loss’ we could pass
output_transform=lambda loss: {"batchloss": loss} - Ignite also provides the flexibility to execute custom event handlers, these can be set with
log_handlerattribute of theattach_output_handler. For example,log_handler=WeightsScalarHandler(model)would log the norm of model’s weights.
def run(train_batch_size, val_batch_size, epochs, lr, momentum):
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
model = Net()
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
model.to(device)
optimizer = SGD(model.parameters(), lr=lr, momentum=momentum)
criterion = nn.CrossEntropyLoss()
trainer = create_supervised_trainer(model, optimizer, criterion, device=device)
trainer.logger = setup_logger("Trainer")
metrics = {"accuracy": Accuracy(), "loss": Loss(criterion)}
train_evaluator = create_supervised_evaluator(model, metrics=metrics, device=device)
train_evaluator.logger = setup_logger("Train Evaluator")
validation_evaluator = create_supervised_evaluator(model, metrics=metrics, device=device)
validation_evaluator.logger = setup_logger("Val Evaluator")
@trainer.on(Events.EPOCH_COMPLETED)
def compute_metrics(engine):
train_evaluator.run(train_loader)
validation_evaluator.run(val_loader)
# To utilize other loggers we need to change the object here
clearml_logger = ClearMLLogger(project_name="examples", task_name="ignite")
# Attach the logger to the trainer to log training loss
clearml_logger.attach_output_handler(
trainer,
event_name=Events.ITERATION_COMPLETED(every=100),
tag="training",
output_transform=lambda loss: {"batchloss": loss},
)
# Attach the logger to log loss and accuracy for both training and validation
for tag, evaluator in [("training metrics", train_evaluator), ("validation metrics", validation_evaluator)]:
clearml_logger.attach_output_handler(
evaluator,
event_name=Events.EPOCH_COMPLETED,
tag=tag,
metric_names=["loss", "accuracy"],
global_step_transform=global_step_from_engine(trainer),
)
# Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate
clearml_logger.attach_opt_params_handler(
trainer, event_name=Events.ITERATION_COMPLETED(every=100), optimizer=optimizer
)
# Attach the logger to the trainer to log model's weights norm
clearml_logger.attach(
trainer, log_handler=WeightsScalarHandler(model), event_name=Events.ITERATION_COMPLETED(every=100)
)
# Attach the logger to the trainer to log model's weights as a histogram
clearml_logger.attach(trainer, log_handler=WeightsHistHandler(model), event_name=Events.EPOCH_COMPLETED(every=100))
# Attach the logger to the trainer to log model’s gradients as scalars
clearml_logger.attach(
trainer, log_handler=GradsScalarHandler(model), event_name=Events.ITERATION_COMPLETED(every=100)
)
#Attach the logger to the trainer to log model's gradients as a histogram
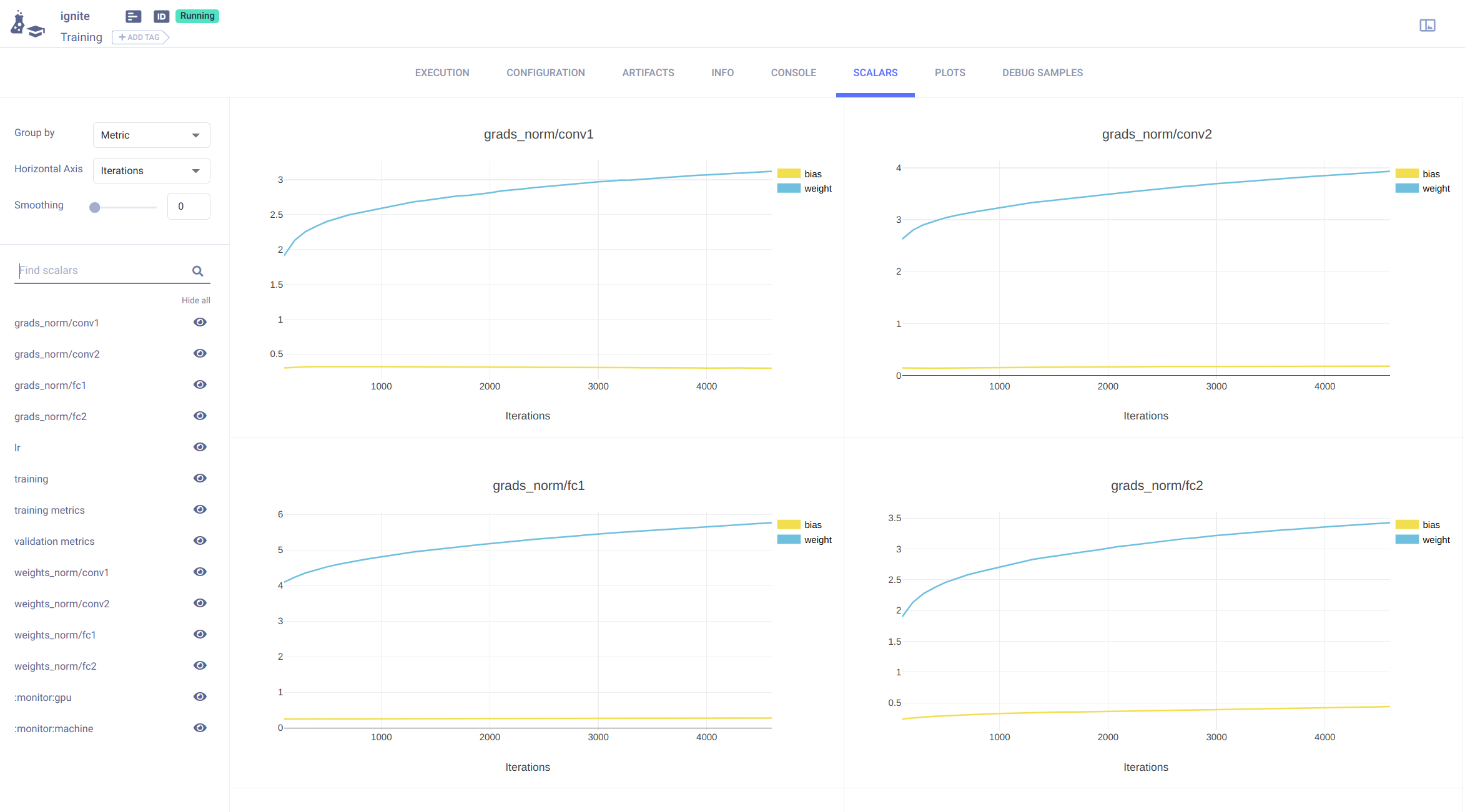
clearml_logger.attach(trainer, log_handler=GradsHistHandler(model), event_name=Events.EPOCH_COMPLETED(every=100))
handler = Checkpoint(
{"model": model},
ClearMLSaver(),
n_saved=1,
score_function=lambda e: e.state.metrics["accuracy"],
score_name="val_acc",
filename_prefix="best",
global_step_transform=global_step_from_engine(trainer),
)
validation_evaluator.add_event_handler(Events.EPOCH_COMPLETED, handler)
trainer.run(train_loader, max_epochs=epochs)
clearml_logger.close()
batch_size=64
val_batch_size=1000
epochs=5
lr=0.01
momentum=0.5
run(batch_size, val_batch_size, epochs, lr, momentum)
ClearML Task: created new task id=575b4d9b5c8a47589ac7edb7e5e0bb59
ClearML results page: https://app.community.clear.ml/projects/4d6b8ac509bc46da91607e83011248fb/experiments/575b4d9b5c8a47589ac7edb7e5e0bb59/output/log
/home/anirudh/miniconda3/envs/ignite/lib/python3.9/site-packages/ignite/contrib/handlers/clearml_logger.py:659: UserWarning: ClearMLSaver created a temporary checkpoints directory: /tmp/ignite_checkpoints_2021_10_25_20_21_50_gkx2f03c
warnings.warn(f"ClearMLSaver created a temporary checkpoints directory: {dirname}")
2021-10-25 20:21:50,778 Trainer INFO: Engine run starting with max_epochs=5.
2021-10-25 20:22:08,993 Train Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:22:18,656 Train Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:10
2021-10-25 20:22:18,657 Train Evaluator INFO: Engine run complete. Time taken: 00:00:10
2021-10-25 20:22:18,658 Val Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:22:29,442 Val Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:11
2021-10-25 20:22:29,443 Val Evaluator INFO: Engine run complete. Time taken: 00:00:11
2021-10-25 20:22:29,444 Trainer INFO: Epoch[1] Complete. Time taken: 00:00:39
2021-10-25 20:22:46,879 Train Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:22:57,516 Train Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:11
2021-10-25 20:22:57,518 Train Evaluator INFO: Engine run complete. Time taken: 00:00:11
2021-10-25 20:22:57,519 Val Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:23:12,853 Val Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:15
2021-10-25 20:23:12,854 Val Evaluator INFO: Engine run complete. Time taken: 00:00:15
2021-10-25 20:23:12,855 Trainer INFO: Epoch[2] Complete. Time taken: 00:00:43
2021-10-25 20:23:29,609 Train Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:23:40,388 Train Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:11
2021-10-25 20:23:40,390 Train Evaluator INFO: Engine run complete. Time taken: 00:00:11
2021-10-25 20:23:40,390 Val Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:23:55,842 Val Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:15
2021-10-25 20:23:55,845 Val Evaluator INFO: Engine run complete. Time taken: 00:00:15
2021-10-25 20:23:55,845 Trainer INFO: Epoch[3] Complete. Time taken: 00:00:43
2021-10-25 20:24:13,223 Train Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:24:23,924 Train Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:11
2021-10-25 20:24:23,925 Train Evaluator INFO: Engine run complete. Time taken: 00:00:11
2021-10-25 20:24:23,925 Val Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:24:39,658 Val Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:16
2021-10-25 20:24:39,661 Val Evaluator INFO: Engine run complete. Time taken: 00:00:16
2021-10-25 20:24:39,662 Trainer INFO: Epoch[4] Complete. Time taken: 00:00:44
2021-10-25 20:24:57,385 Train Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:25:07,264 Train Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:10
2021-10-25 20:25:07,265 Train Evaluator INFO: Engine run complete. Time taken: 00:00:10
2021-10-25 20:25:07,267 Val Evaluator INFO: Engine run starting with max_epochs=1.
2021-10-25 20:25:22,536 Val Evaluator INFO: Epoch[1] Complete. Time taken: 00:00:15
2021-10-25 20:25:22,537 Val Evaluator INFO: Engine run complete. Time taken: 00:00:15
2021-10-25 20:25:22,538 Trainer INFO: Epoch[5] Complete. Time taken: 00:00:43
2021-10-25 20:25:22,539 Trainer INFO: Engine run complete. Time taken: 00:03:32
If you followed along, Congratulations! You can take a look at some of the visualisations from the results page mentioned in you logs above (ClearML results page). Here’s an example!