
Hey, I’m Sangho Lee, a master’s student from Seoul National University. I have participated in the PyTorch-Ignite project internship at Quansight Labs, working on test code improvements and features for distributed computations.
Crossposted from https://labs.quansight.org/blog/sangho-internship-blogpost
The first part of my contributions is improvements to the test code for metric computation in Distributed Data Parallel (DDP) configuration.
Then I worked on adding the group argument to the all_reduce and all_gather methods in
ignite.distributed module.
About PyTorch-Ignite and distributed computations
PyTorch-Ignite is a high-level library which helps with training and evaluating neural networks in PyTorch flexibly and transparently. By using PyTorch-Ignite, we can get the benefit of less code than pure PyTorch and extensible API for metrics, experiments, and other components. In this point of view, PyTorch-Ignite also supports distributed computations with the PyTorch-Ignite distributed module for distributed computations.
When you train a batch of datasets larger than your machine’s capacity, then you need to parallelize computations by distributing data.
From this situation, Distributed Data-Parallel(DDP) training is widely adopted when training in distributed configuration with PyTorch.
With DDP, the model is replicated on every process, and every model replica will be fed with a different set of input data samples.
However, when we use another backend like horovod or xla, then we should rewrite the code for each configuration.
PyTorch-Ignite distributed module (ignite.distributed) is a helper module to use distributed settings for multiple backends like nccl, gloo, mpi, xla, and horovod, accordingly, we can use ignite.distributed for distributed computations regardless of backend.
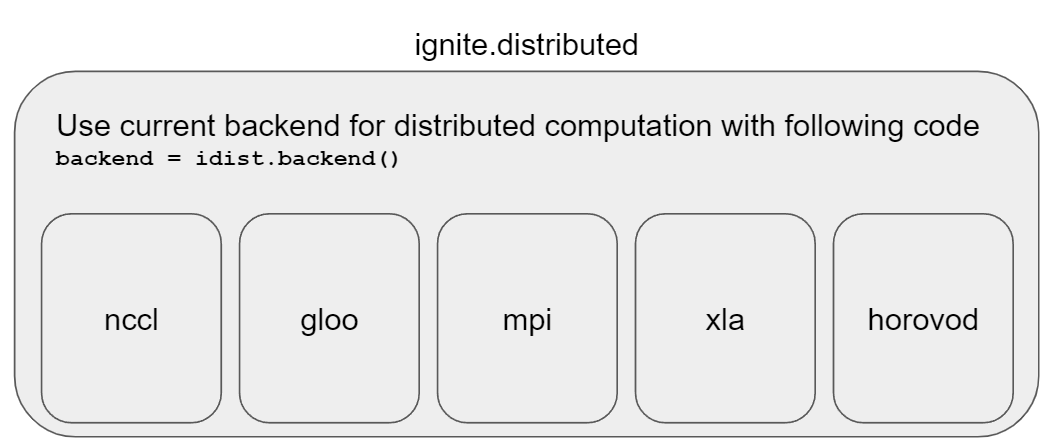
By simply designating the current backend, ignite.distributed provides a context manager to simplify the code of distributed configuration setup for all above supported backends. And it also provides methods for using existing configurations from each backend.
For example, auto_model, auto_optim or auto_dataloader helps provided model to adapt existing configuration and Parallel helps
to simplify distributed configuration setup for multiple backends.
How I contributed with improving test code in DDP config
Problem : test code for metrics computation has incorrectly implemented correctness checks in a distributed configuration
There are 3 items to be checked to ensure that the test code for each metric works correctly in DDP configuration.
- Generate random input data on each rank and make sure it is different on each rank. This input data is used to compute a metric value with ignite.
- Gather data with
idist.all_gatheron each rank such that they have the same data before computing reference metric - Compare the computed metric value with the reference value (e.g. computed with scikit-learn)
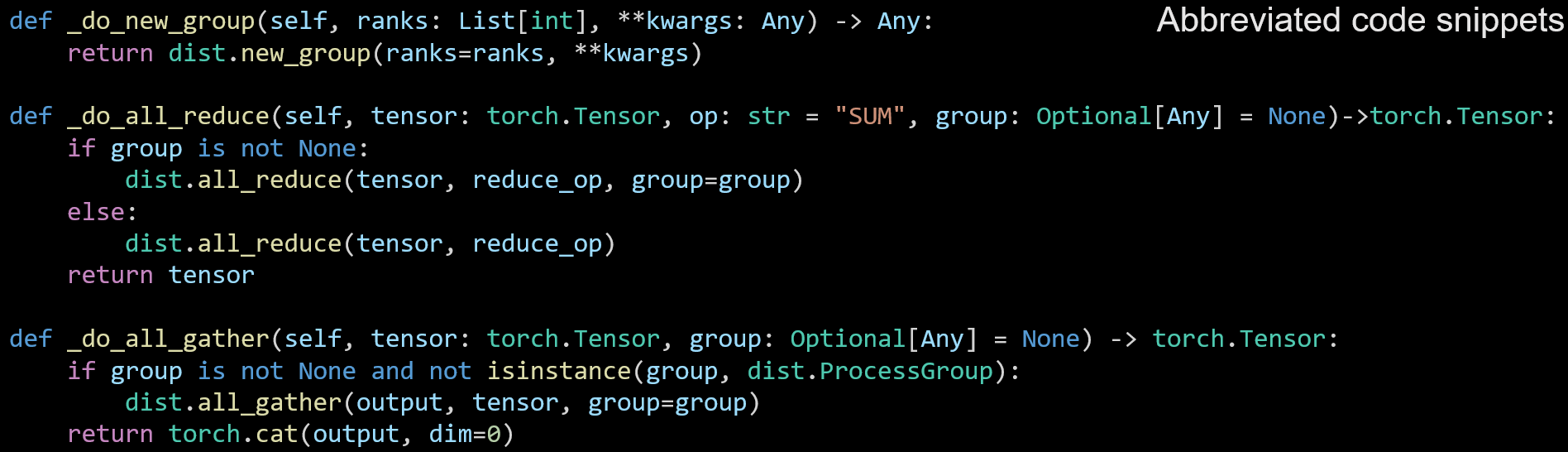
How I contributed new feature: group argument to all_reduce and all_gather methods
Problem : Existing methods in PyTorch-Ignite uses all ranks, however, for certain use cases users may want to choose a subset of ranks for collecting the data like in the picture.
As mentioned, the distributed part of Ignite is a wrapper of different backends like
horovod,
nccl,
gloo and
xla.
I added a new group method for generating group depending on its backend and modified all_reduce and all_gather to take group arguments for users to select the devices.
My contributions
What I learned
These 3 months were really precious time for me as an intern of Quansight.
PS: I want to thank my mentor Victor Fomin for the teaching and support during the internship.